Getting Started#
System Requirements#
Chip: 4 core mínimo
Processor: 2.5GHz o superior
RAM: 8 GB
Disk: 5 GB libres para instalación
Advertencia
ARM chips no son soportados
Installation#
Windows#
Descarga la última versión desde el repositorio Github
Mac#
Nota
Pronto disponible
Standalone#
Free Trial#
Ingresa al enlace de descarga, y solicita iniciar tu prueba gratis de 30 días. Podrás acceder a todos los módulos con mínimas restricciones que pronto anunciaremos.
Activate#
Accede a la sección de activación y sigue estos pasos:
Crea una cuenta
Valida la cuenta desde tu e-mail
Elige el plan que más se acomode a tu necesidad
Realiza el proceso de pago
Espera un momento hasta recibir un token y copialo al portapapeles
Abre vtarget y pega el texto en el popup que solicita la llave de activación
Haz click en aceptar y espera un momento hasta realizar la activación
Upgrade#
Cuando exista una nueva versión recibirás una alerta al abrir vtarget, solo debes aceptar la actualización y se instalará automáticamente.
Quickstart#
Esta guía es una descripción general y explica las características importantes; los detalles se encuentran en Modules.
Home#
Es la pantalla de bienvenida luego de iniciar sesión, la primera vez que ingreses tendrá estos elementos.
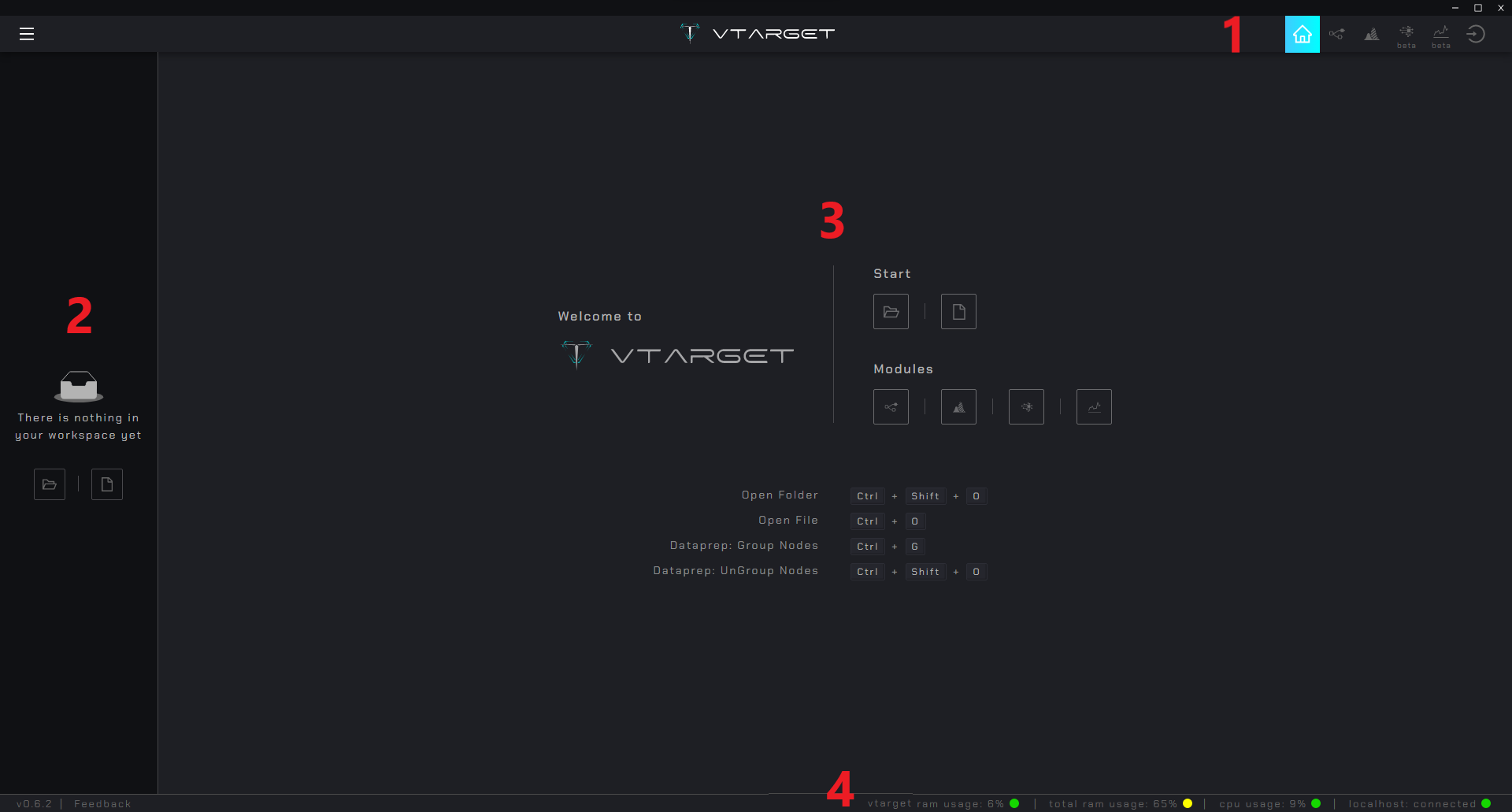
Navbar: Navegación entre el
Homey los 4 módulosDataPrep,DataViz,AutoMLyAutoTSL-Sidebar: Panel de navegación de directorio
Content: Área principal, en el
Homecontiene accesos a módulos y shortcutsFooter: Entrega información de rendimiento del procesador y estado de conección con los workers
DataPrep#
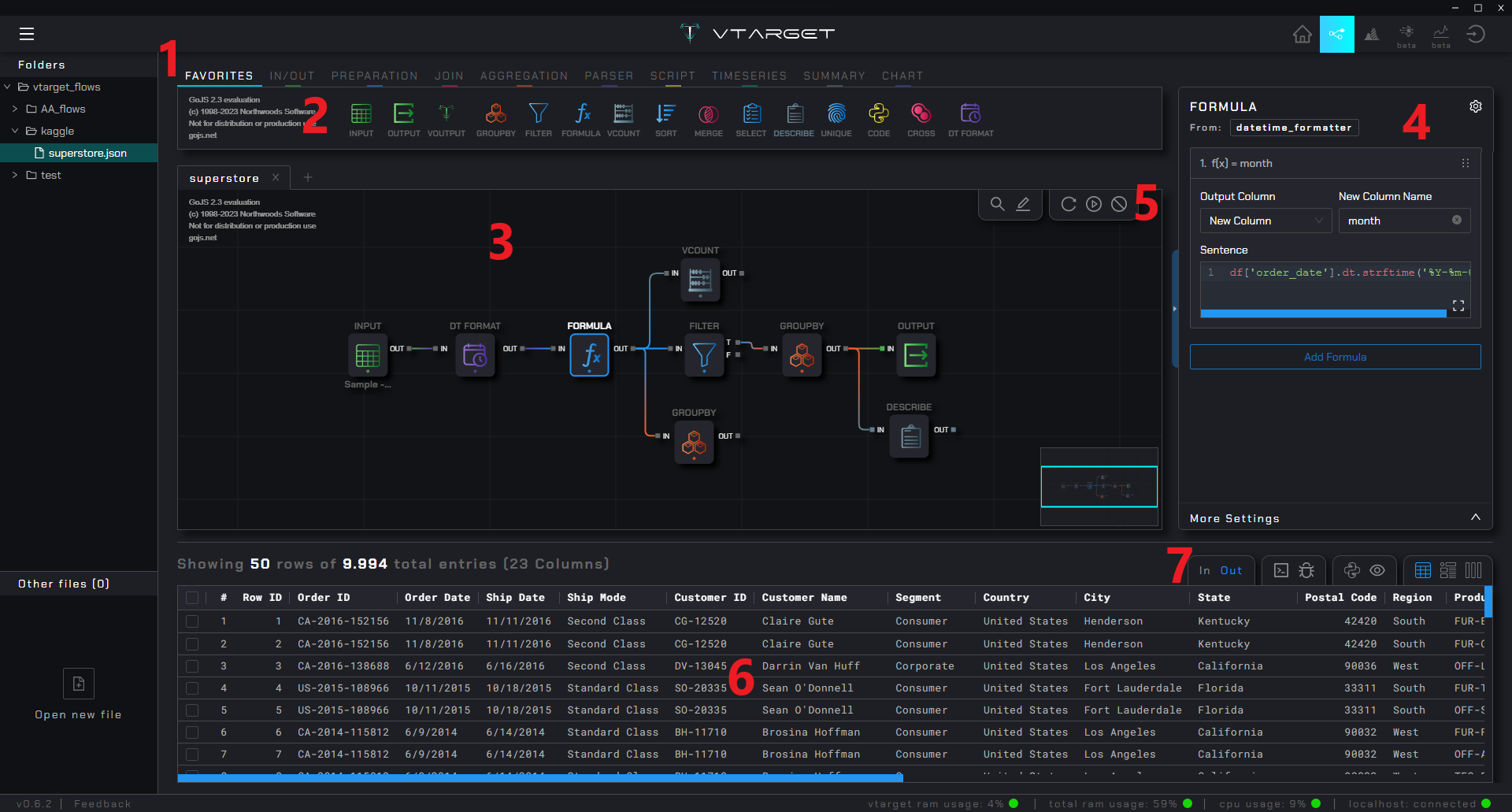
Node group: Menu para seleccionar el grupo de nodos requerido
Palette: Zona donde se muestran todos los nodos de un grupo, puedes arrastrarlos hacia el canvas para conectar con otros nodos
Canvas: Área dónde sueltas un nodo, y conectas con otros para crear un flujo. Te puedes mover libremente y no tienes límites de espacio, puedes dar la forma que tu quieras
R-sidebar setting: Panel para realizar la configuración de un nodo. Solo se despliega cuando un nodo tiene un foco (mantiene el estándar de
Pandas)Execution controls: Grupo de botónes para ejecución de flujos y otro grupo para búsqueda de nodos y escribir comentarios en el canvas
Result zone: Muestra información asociada al resultado de cada nodo, cambia dependiendo de la opción seleccionada en la esquina superior izquierda
Result controls: Controla la salida que se quiera ver del nodo seleccionado: puertos de entrada y salida, consola de log, depuración, código python auto-generado y 3 tipos de visualización de tabla (compacta, detallada y por columna)
DataViz#
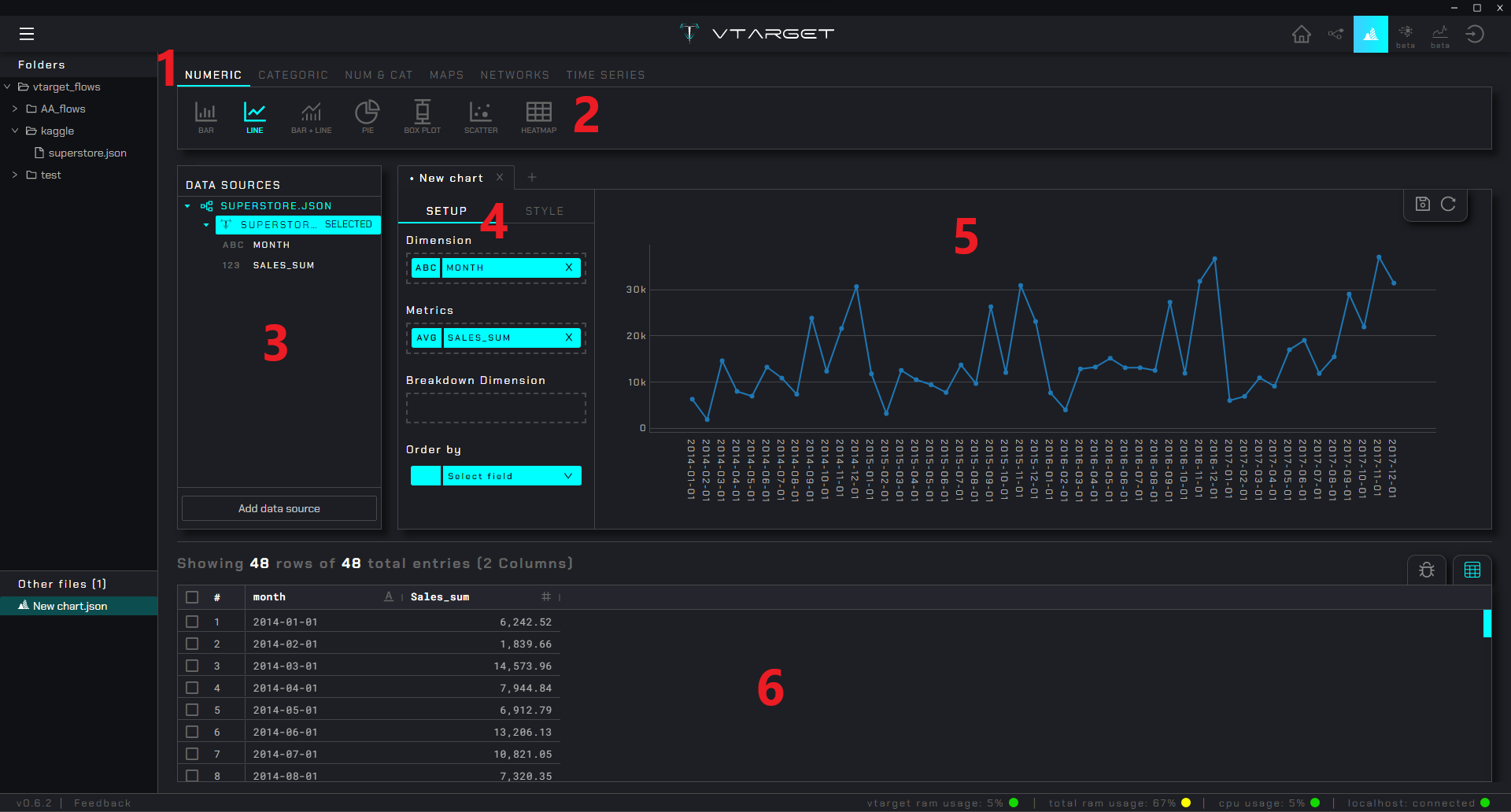
Plot group: Menu que agrupa gráficos según el tipo de variable que soportan
Plots: Lista de gráficos disponibles pertenecientes al grupo seleccionado
Data-sources panel: Lista de las fuentes de datos cargadas y sus variabes que pueden ser arrastradas a la configuración del gráfico
Setting panel: Panel de configuración para cada gráfico (cambios toman efecto en tiempo real)
Plot view: Visualización del gráfico con la configuración dada
Data source view: Tabla asociada a la fuente de datos seleccionada
AutoML#

Step Menu: Contiene los pasos para configurar el modelado de problemas binarios, multiclase y regresores
Content zone: Muestra las configuraciones y opciones asociada al menú seleccionado
Nota
La imagen de referencia muestra la configuración de un modelo binario, sin embargo para multiclase y regresores el proceso es el mismo:
DATA SOURCE: Selecciona la fuente ya sea de un nodo
voutput(del módulodataprep) o desde un archivo csv externoSETUP: Elige la
variable objetivoy se infiere automáticamente eltipo de problema(puedes cambiarlo en caso de error)FEATURES Configura el particionado, elige la
métrica objetivoy selecciona qué variables usarás en el entrenamiento (también se genera automáticamente un análisis descriptivo de cada variable)MODEL: Realiza automáticamente el proceso de entrenamiento iterando distintos
modelos,pipelinesehiper-parámetros. Permite examinar cada modelo y visualizar métricas de rendimiento. En la medida que se entrenan se ordenan por la mejor métrica objetivo.PREDICTION: Genera predicciones con el
mejor modelo recomendado
AutoTS#
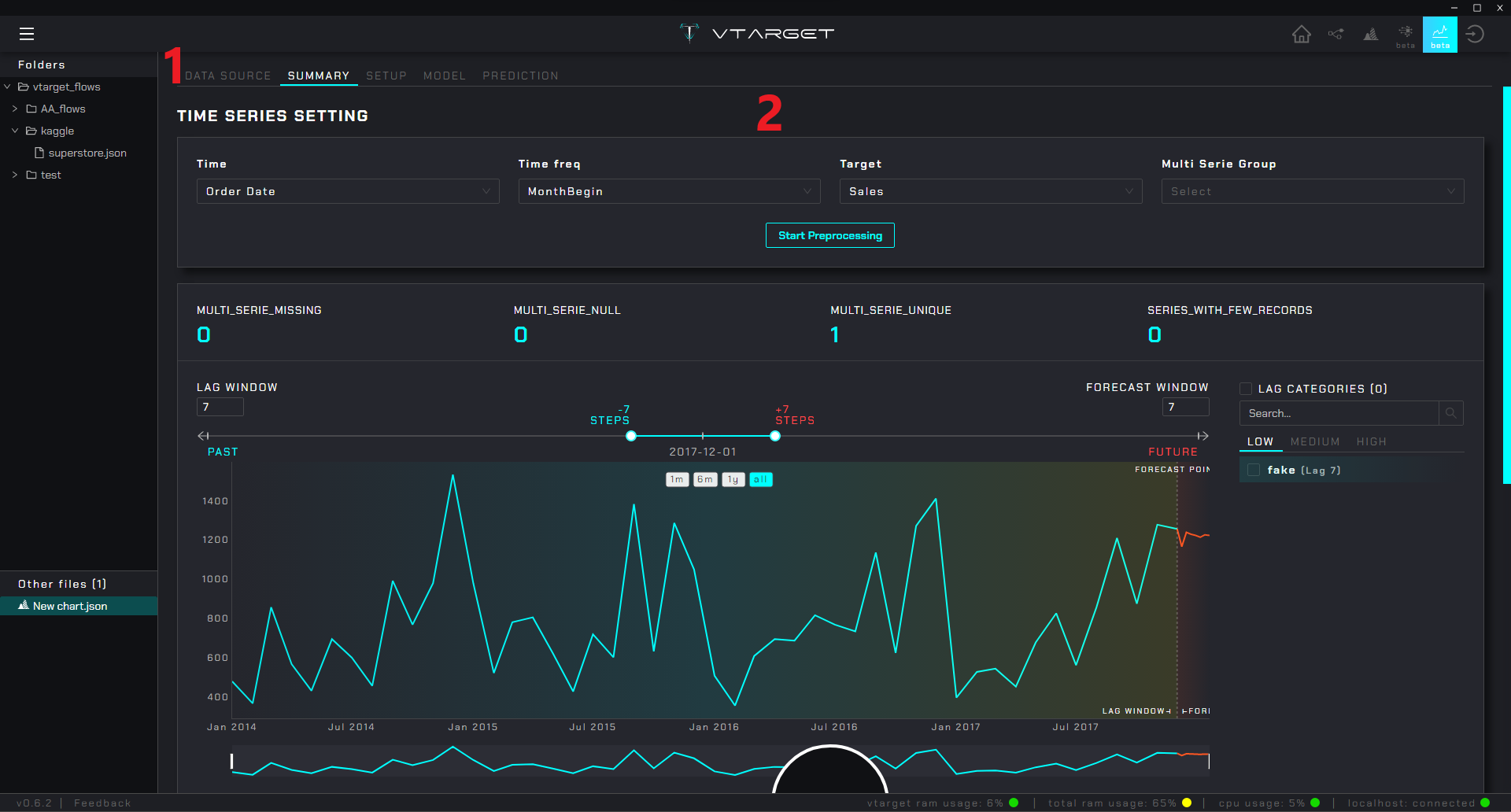
Step Menu: Contiene los pasos para configurar el modelado series de tiempo
Content zone: Muestra las configuraciones y opciones asociada al menú seleccionado
Nota
La imagen de referencia muestra el resumen luego de seleccionar la columna asociada al tiempo, la frecuencia de la serie y el target. En el caso de forecast el menú sigue la siguiente lógica:
DATA SOURCE: Selecciona la fuente ya sea de un nodo
voutput(del módulodataprep) o desde un archivo csv externoSUMMARY: Genera una resumen de la/las series, se crea una visualización de cada serie y automáticamente se categoriza según so
coeficiente de variabilidaden LOW, MEDIUM y HIGH. En la parte inferior de la pantalla se genera un resumen general de la serie seleccionadaSETUP: Configura el particionado, elige la
métrica objetivoy selecciona qué variables usarás en el entrenamiento (también se genera automáticamente un resumen estadístico de las series con la configuración dada)MODEL: Realiza automáticamente el proceso de entrenamiento iterando distintos
modelos,pipelinesehiper-parámetros. Permite examinar cada modelo y visualizar métricas de rendimiento. En la medida que se entrenan se ordenan por la mejorPREDICTION: Valida o genera predicciones para una serie determinada con el
mejor modelo recomendado(o cualquier otro)